
Finding Trump with Neural Networks

Prior to March 2018 Donald Trump had been using an unauthorised personal Android phone in his role as POTUS. Whilst a source of anxiety for his Staff, for journalists and researchers this was particularly useful for distinguishing the words of the President himself, from those of the White House Staff. With Twitter’s API — the gateway Twitter makes available for anyone wanting to utilise their data — providing information on the ‘source’ for each Tweet, it became a fair assumption that if the ‘source’ was Android, it was pure Trump.
However as you can see from the following chart that maps the month of the tweet (on the x axis) by the frequency of tweeting (on the y axis), around March 2017 activity from Android drops off, and iPhone activity picks up.
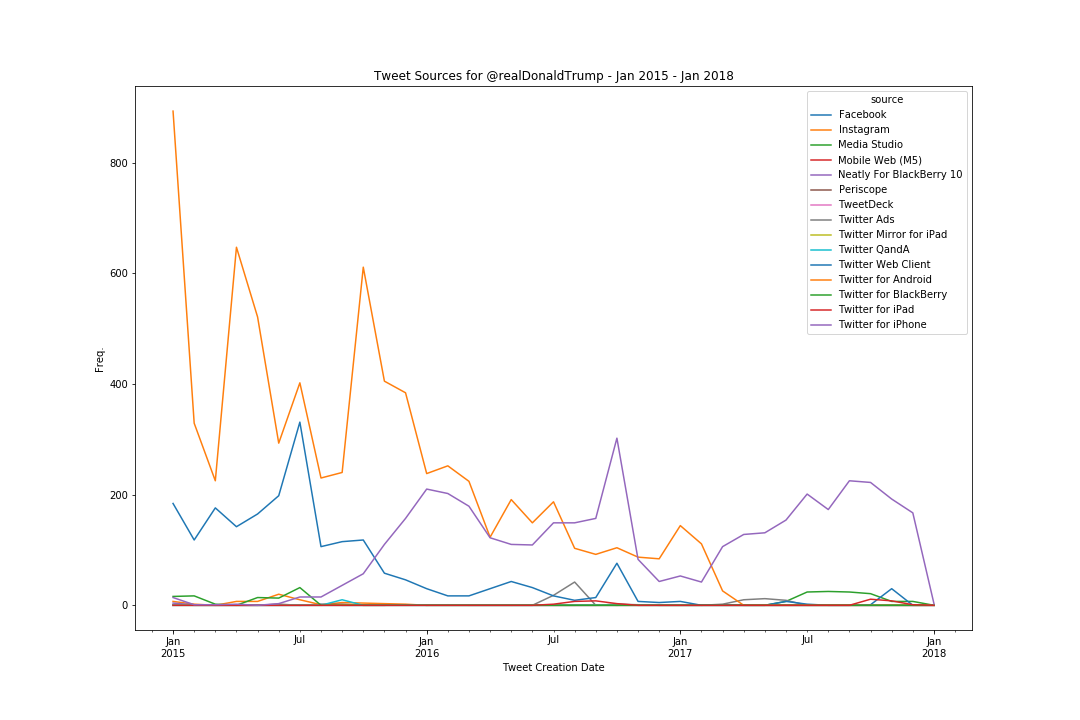
As Dan Scavino Jr., White House Director of Social Media revealed, Trump had been moved to an iPhone mid-March. Speculation from the press was that the change was motivated by matters of security, with the personal Android evading the institutional management of the White House. Whilst good for White House Staff, the (un)intended consequence has also meant the tweets written by Trump himself are now in the mix with those written by his Staff on the POTUS account. As Twitter has become such a key component of White House communication, and with the abnormal state of affairs that is this American Presidency, being able to distinguish the Tweets of the president himself from his Staff has become rather important. Enter the computational solution! — A neural network trained to recognise a Trump authored tweet by the tweet text alone.
Before we start…
First and foremost, it should be noted that this modelling was purely an exercise. I enjoy technical diversions and excuses to learn new skills. Sometimes those excuses turn into full papers and new courses for my students, but often they get stuck in a digital drawer. A similar exercise to this has already been done using other Machine Learning techniques, and I’d encourage anyone interested to go and read up on it.
For this particular project however, I will be seeing whether we can train a Neural Network to recognise Trump purely by the text of the tweet. Neural networks are computer simulations that operate similarly to the way our brains work. They have highly interconnected sets of artificial neurons and can adapt and change themselves based on the data that flows through them. For this network’s data I used the Trump Twitter Archive which provides a repository of Trump account tweets going back to 2009. Unfortunately, data archiving appears to have stopped at January 2018 but we’ll work with what we’ve got for the exercise. For the programmatically-minded a narrated notebook detailing the code is available, but my aim is to give non-programmer social scientists a gist of how these processes work so that they might consider them for their own projects.
Checking the Data
To begin with I loaded the condensed datasets for 2015, 2016 and 2017 into a DataFrame, dropping all retweets as these would contain text not from Trump or his Staff. You could add in the 2018 dataset but it ends mid-January.

First, I took a quick look at the data to see what kinds of sources were being used on the account and their activity. The top 3 sources for the account across the whole combined dataset were Android, iPhone and the Twitter Web Client, though this last one appears to be most active prior to Trump’s announcement to run in the Presidential election in June 2015. Looking at a few examples from the Twitter Web Client it is not entirely clear whether it is Donald on the Web Client, or an aide.
ICYMI, @IvankaTrump’s int. on @TODAYshow discussing @Joan_Rivers & contestant rivalries on @ApprenticeNBC http://t.co/Em7bgj10SM
“@nanaelaine7 @realDonaldTrump only YOU can make it GREAT again. Your plan is the only one inside reality. MAKE AMERICA GREAT with TRUMP”
.@megynkelly recently said that she can’t be wooed by Trump. She is so average in every way, who the hell wants to woo her!
FACT ✔️on “red line” in Syria: HRC “I wasn’t there.” Fact: line drawn in Aug ’12. HRC Secy of State til Feb ’13. https://t.co/4yZjH3TR5B
Whether these should be excluded from the data or classified as Trump or as Staff isn’t immediately clear. For this exercise I left them as Staff as our primary assumption is that Trump tweets from Android, but it would be interesting to return and try other classifications later.
We already know that it was at some point in March 2017 that Trump shifted to an iPhone, so it is worth drilling down and locating the precise day that Android went dark. Using Pandas’ wonderful ability to resample time series data, I reshaped the data into a tweet count for every day between February and April 2017 and split them by source.
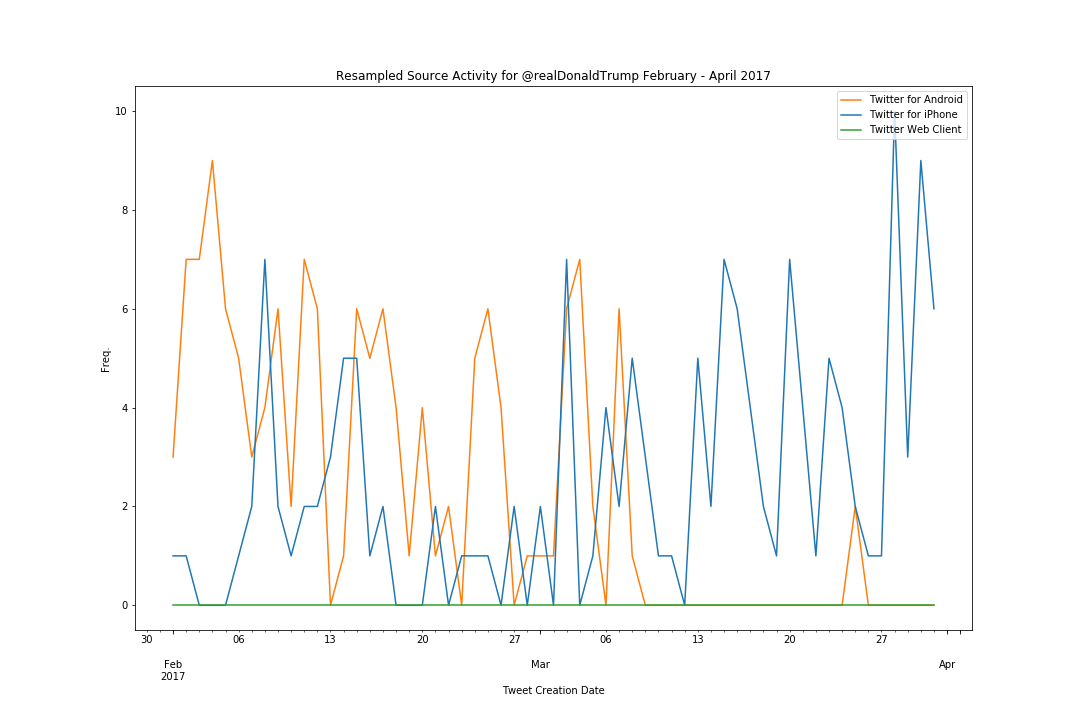
From the chart we can see that in general the last use of the Android phone is on 8 March 2018. Two tweets from Android appear again on March 25 but appear innocuous so for simplicity we’ll disregard them as no more Android Tweets appear from April until the end of the dataset.
Based on this I then split the data into two, pre-iPhone and post-iPhone data. For the pre-iPhone data we can assume that any Android tweets are Trump and any other tweets are Staff. For the post-iPhone data, we can no longer make that assumption. This means that we need to train our neural network model to distinguish Trump and Staff tweets on the pre-iPhone data, and then use that model to predict the source on the post-iPhone data. Easy!
Neural Networks like Numbers - Lots of Numbers
The first step before training the network was to make the words comprehensible for it. We do this by fitting a TFIDF Vectorizer from the Python Library ‘Scikit Learn’ to the entirety of the text data. This stage essentially creates a little model that keeps a record of every unique word across all of the tweets and how prevalent it is across the data. We keep this model handy because we’re going to need it to transform our different sets of text data into a numerical pattern that can be understood by the Neural Network. Vectorizers work by transforming a string of text, into a very wide spreadsheet, with a row for each document, and then a column for each possible word. The values calculated can be the number of times that word occurs in the document, a 1 or a 0 for whether it occurs at all, or in the case of TFIDF, a score based on how significant that word is for that document, considering both the document itself and all the other documents in the dataset. This is demonstrated below with two extracts from Alice in Wonderland and the two row array of TFIDF word scores.


But how does it “know”?! — Training a Neural Network
The way neural networks work for classification, is that they are trained by feeding them lots of examples of your data, and crucially, providing them the expected output or label that the model should predict. With every example the model compares its prediction to the ‘correct’ label, makes adjustments to itself, and tries again. Training continues until it is as close as possible to the ideal scenario of correctly predicting the classification for all instances of the training data. In our case we provide the model lots of tweets, and with each tweet we tell the model whether it is a Trump tweet or a Staff tweet until its prediction is very close to the correct category.
Often after training across many iterations a neural network model will become highly accurate at matching its prediction to the expected outcome, but really, we want to know how well it will perform predicting categories for tweets it has never seen. We can evaluate how well a neural network makes these predictions by holding back a percentage of our training data so that those tweets are never seen by the model in training. We then ask the model to predict the tweet author and check its predictions against the category that we’ve already assigned. For the final model that I built the result was a model that was 97.6% accurate in predicting the labels in the training data it had seen, and 76.8% accurate for tweets it had never seen before. However one doesn’t just build a model. First you build 120 models!
Choosing the right Neural Network for you…
Often when working with text data improvements in machine learning come through better curation of the training data, in our case for example by either focusing just on iPhone and Android Tweets, or considering whether Trump may be responsible for Tweets from other platforms as well. We might also think through whether better pre-processing of the text (cleaning out noise, correctly identifying emoji’s, removing URLs etc.) might be a good decision. However it could also be that these noisy elements are actually the most informative to the model. In our case, after cleaning out the URLs, hashtags and emojis from the tweets, I found the model’s accuracy plummeted by around 20%, indicating that it was these very features that were aiding identification.
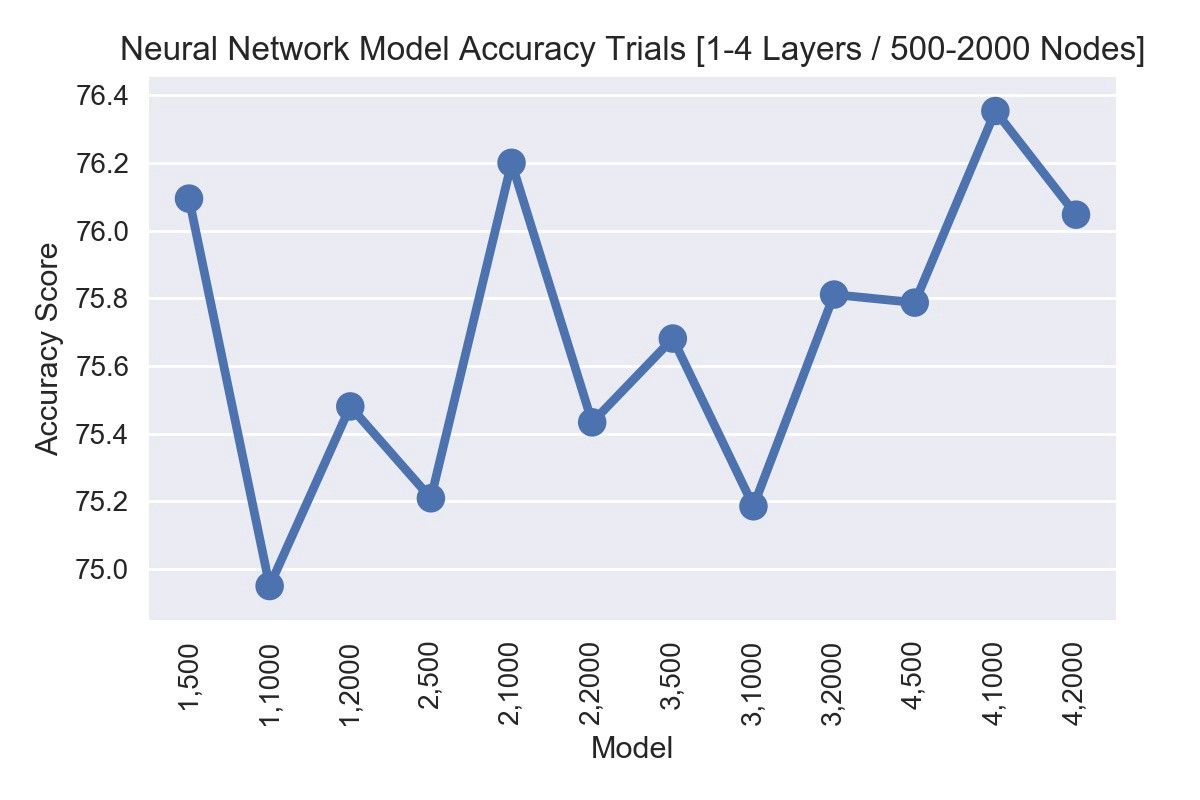
However, crucially a key part of building and using neural networks are the choices made in terms of how many layers your network will have, and how many nodes in each layer. These aren’t necessarily things that can be chosen algorithmically, and they differ depending on the data. One suggestion is to run trials on different model shapes of different amounts of layers and nodes. For every model shape you train and evaluate the model multiple times, each time using a different subset of the training data. For each model shape, you take the average score of its trials, and see in general which model performed best on small chunks of the training data. As you can see after evaluating 120 independently built models, the best result was model 010, a neural network of 4 hidden layers where each hidden layer contained 1000 nodes. Note that simply increasing nodes and layers does not necessarily increase predictive power, the right model ‘shape’ is often dependent on the data you are working with.
The Grand Finale: Finding Trump
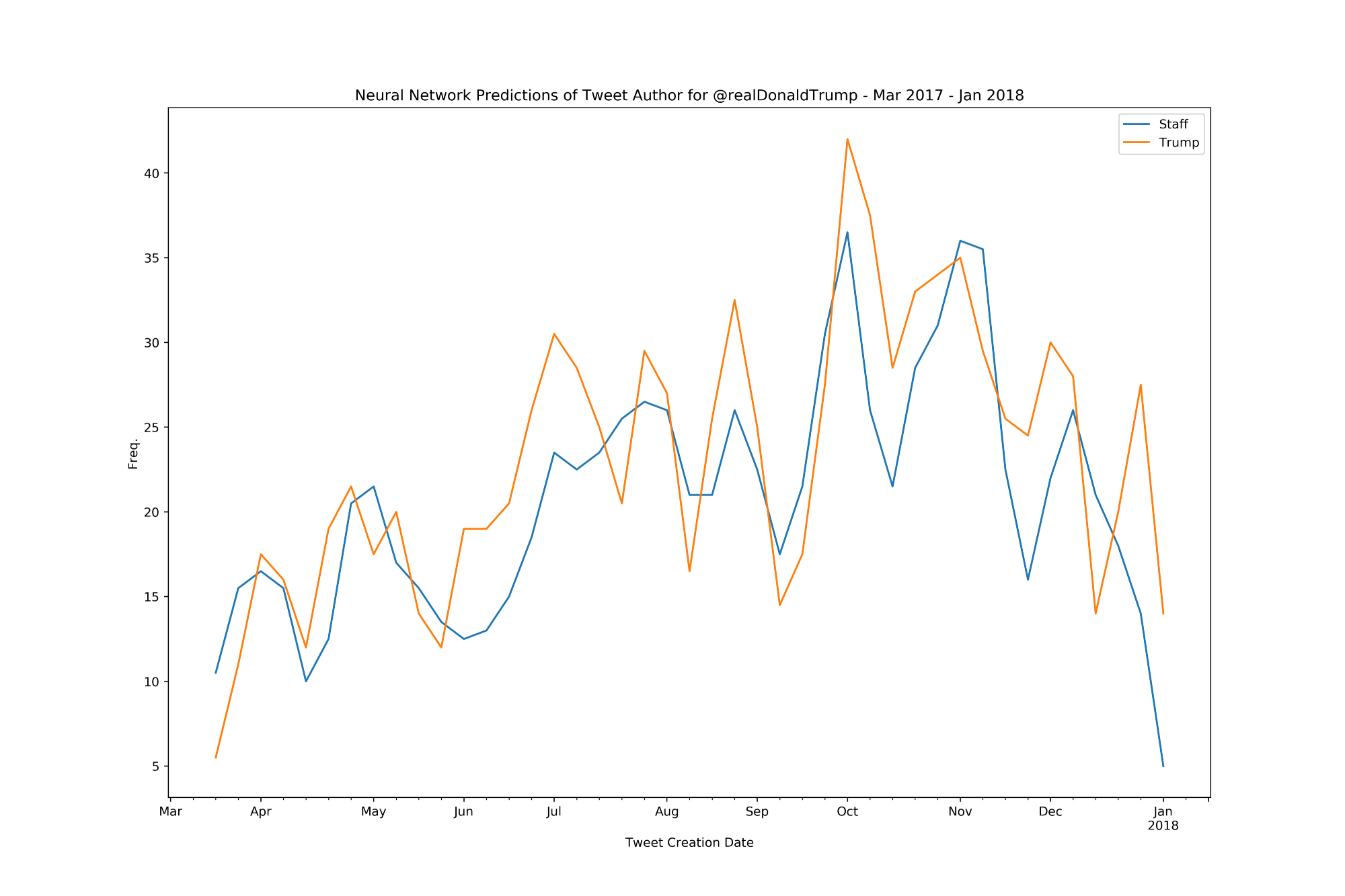
Having determined the best model shape to use (4 hidden layers of 1000 nodes) we build a brand-new model and train it up with all the training data we have and turn to our so far neglected post-iPhone dataset of tweets from after Trump switched to iPhone. In this instance, we have no ‘correct’ labels as we are no longer certain which tweets came from Trump’s phone and which from his Staff as they all come from the iPhone platform. We transform the text using our original TFIDF vectorizer and feed it to the model, asking it to provide us a prediction; Staff or Trump?. In terms of activity we can see the model has a relatively even split between the tweets, with more predicted activity from Staff on some days, and more predicted activity from Trump on others.
Keeping in mind the model’s accuracy of around 77% on unseen data, it is worth inspecting Tweets individually to see how well, on a qualitative level, we believe the model performed. Sampling a random 10 from each category provides us a good overview. For those Tweets predicted as Trump authored we see as lot of exclamation marks, a lot of emphatic strong wording, some anti-Democrat mudslinging and lots of interaction with good ol’ Fox and Friends. The Staff tweets often publish with a URL, speak more in a detatched mode and like to thank and congratulate various citizens in their endeavours. For each prediction you can see how confident the model is in its own prediction, with 1 meaning absolutely confident, and 0 meaning no confidence.
Predicted Trump Tweets
| text | prediction_score | created_at | source |
|---|---|---|---|
| Will be having meetings and working the phones from the Winter White House in Florida (Mar-a-Lago). Stock Market hit new Record High yesterday - $5.5 trillion gain since E. Many companies coming back to the U.S. Military building up and getting very strong. | 0.997469902 | 22/11/2017 11:51 | Twitter for iPhone |
| "The first 90 days of my presidency has exposed the total failure of the last eight years of foreign policy!" So true. @foxandfriends | 0.976731896 | 17/04/2017 12:07 | Twitter for iPhone |
| The Democrats only want to increase taxes and obstruct. That's all they are good at! | 0.999997139 | 16/10/2017 12:21 | Twitter for iPhone |
| ...Why did the DNC REFUSE to turn over its Server to the FBI, and still hasn't? It's all a big Dem scam and excuse for losing the election! | 0.995055676 | 22/06/2017 14:08 | Twitter for iPhone |
| Jeff Flake, with an 18% approval rating in Arizona, said "a lot of my colleagues have spoken out." Really, they just gave me a standing O! | 0.999713838 | 25/10/2017 12:33 | Twitter for iPhone |
| If Chelsea Clinton were asked to hold the seat for her mother,as her mother gave our country away, the Fake News would say CHELSEA FOR PRES! | 0.730919182 | 10/07/2017 11:47 | Twitter for iPhone |
| I will represent our country well and fight for its interests! Fake News Media will never cover me accurately but who cares! We will #MAGA! | 0.999840736 | 07/07/2017 07:44 | Twitter for iPhone |
| Big ratings getter @seanhannity and Apprentice Champion John Rich are right now going on stage in Las Vegas for #VegasStrong. Great Show! | 0.999996424 | 20/10/2017 03:00 | Twitter for iPhone |
| Rather than causing a big disruption in N.Y.C., I will be working out of my home in Bedminster, N.J. this weekend. Also saves country money! | 0.997959018 | 05/05/2017 13:02 | Twitter for iPhone |
| ISIS just claimed the Degenerate Animal who killed, and so badly wounded, the wonderful people on the West Side, was "their soldier." ..... | 0.999863148 | 03/11/2017 12:03 | Twitter for iPhone |
Predicted Staff Tweets
| text | prediction_score | created_at | source |
|---|---|---|---|
| Billions of dollars in investments & thousands of new jobs in America! An initiative via Corning, Merck & Pfizer: https://t.co/QneN48bSiq https://t.co/5VtMfuY3PM | 0.999972105 | 21/07/2017 03:31 | Twitter for iPhone |
| #WeeklyAddress 🇺🇸 ➡️ https://t.co/uT4K4fh88Y https://t.co/1iW7tVVNCH | 0.876031041 | 13/05/2017 00:47 | Twitter Ads |
| A must watch: Legal Scholar Alan Dershowitz was just on @foxandfriends talking of what is going on with respect to the greatest Witch Hunt in U.S. political history. Enjoy! | 0.99896729 | 04/12/2017 12:35 | Twitter for iPhone |
| We need a tax system that is FAIR to working families & that encourages companies to STAY in America, GROW in America, and HIRE in America 🇺🇸 https://t.co/u9ZgijgLE3 | 0.999088407 | 11/10/2017 23:28 | Twitter for iPhone |
| We must remember this truth: No matter our color, creed, religion or political party, we are ALL AMERICANS FIRST. https://t.co/FesMiQSKKn | 1 | 12/08/2017 21:19 | Media Studio |
| To each member of the graduating class from the National Academy at Quantico, CONGRATULATIONS! https://t.co/bGT8S33ZLU | 0.999998689 | 15/12/2017 17:35 | Twitter for iPhone |
| I've been saying it for a long, long time. #NoKo https://t.co/LQl7tGhMdO | 1 | 28/12/2017 19:20 | Twitter for iPad |
| Today I am here to offer a renewed partnership with America -- to work together to strengthen the bonds of friendship and commerce between all of the nations of the Indo-Pacific, and together, to promote our prosperity and security. #APEC2017 https://t.co/gN2YbS9CYB | 0.995637 | 10/11/2017 10:06 | Twitter Web Client |
| We were let down by all of the Democrats and a few Republicans. Most Republicans were loyal, terrific & worked really hard. We will return! | 0.999987483 | 18/07/2017 11:53 | Twitter for iPhone |
| .@DanaPerino & @BradThor, Thank you so much for the wonderful compliment. Working hard! #MAGA https://t.co/AKWlsMsCVH | 0.99979645 | 18/10/2017 23:31 | Twitter for iPhone |
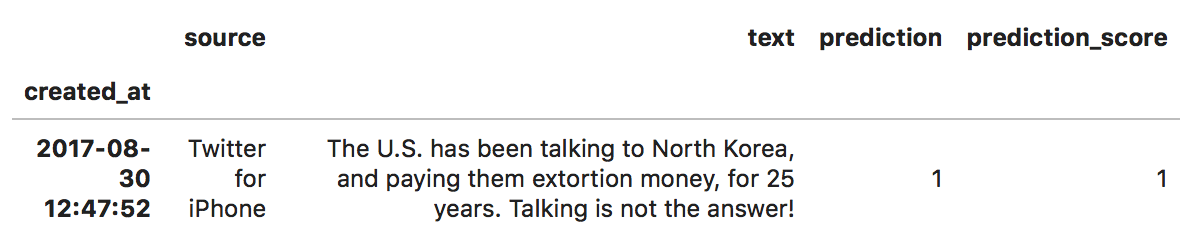
For any politician, having multiple people ‘speak’ through an account identified to be one individual can make it difficult for the public to get a handle on who their elected official really is. It can also add uncertainty for those wishing to hold those poltiicans to account when it could be plausibly claimed that they never wrote that problematic tweet in the first place. However according to this model at least, this is 100% Trump, with 100% confidence.
If you’re interested in playing around with Neural Networks yourself, or want the details on precisely how I went about building the model, the code for this diversion is available as a Jupyter Notebook.
This diversion was supported in part by the ESRC Human Rights, Big Data and Technology Project at the University of Essex.
This work was supported by the Economic and Social Research Council [grant number ES/ M010236/1]